Как правильно проверить частотность поисковых запросов в Яндексе и очистить их от "мусора"? Какими операторами пользоваться для максимальной детализации ключевых слов? Как проверить базовую и точную частотность? Обо всем подробнее в данной статье.
Частотность - это количество показов поисковых запросов, набранных пользователями за определенный промежуток времени. В сервисе Яндекс WordStat данная статистика отображается за месяц. Большинство вебмастеров и владельцев сайтов знакомы с данным сервисом, однако, даже многие опытные специалисты до конца не понимают всю прикладную мощь данного инструмента .
Проверка частотности запросов в Яндексе для "чайников"
Для того, чтобы проверить базовую частотность, необходимо в поисковую строку WordStat вбить искомое ключевое слово. По-умолчанию статистика отображается по всем регионам и устройствам, однако, вы можете ее детализировать по десктопам, мобильным устройствам, только телефонам и только планшетам. Кроме того, сервис автоматически показывает похожие ключевые слова, предоставляет возможность посмотреть историю конкретных поисковых запросов за 2 года, а также детализировать запросы по регионам и городам. В данной статье мы рассмотрим только статистику по ключевым словам, всем устройствам и регионам WordStat.
Рассмотрим отображение базовой частотности WordStat по запросу "купить замОк".
Так, цифра 244 253 рядом c фразой «купить замок» обозначает число показов в месяц по всем запросам с ключевым словом «купить замок» : «купить замок зажигания», «купить замок на дверь», «где купить замок», «купить дверной замок» и т.п. Верхнее число показов - это сумма всех нижестоящих показов по всем отображенным словам .
Но как в таком случае проверить количество показов строго по запросу "купить замок" (дверной), убрав весь нетематических мусор: "детские зАмки", "замки зажигания", "замок автомобиля" и т.п. Для этого существуют операторы WordStat .
6 операторов для уточнения запросов
Операторы WordStat - это символы, которые помогут вам точнее сформулировать ключевую фразу для получения статистики. Их на данный момент существует 6.
| Оператор | Что делает | Пример ключевой фразы | Отображение статистики |
| ! | Жестко фиксирует слово (время, род, число, падеж) | купить замок в!москве |
|
| " " | Кавычки фиксируют количество слов в запросе | "купить замок" |
|
| + | Плюс фиксирует все частицы, предлоги и служебные слова в запросе. По-умолчанию они игнорируются | купить замок +на дверь |
|
| - | Минус удаляет все лишние слова из запроса | купить замок -автомобиля |
|
| Квадратные скобки фиксируют порядок слов в запросе | купить [замок дверной] |
|
|
| () и | | Пайп (вертикальная черта) и круглые скобки помогают при группировке сложных запросов | купить замок (недорого|дверной) |
|
Вся прелесть операторов заключается в том, что их можно использовать друг с другом. Совместное использование операторов для детализации запросов дает хорошему вебмастеру мощный seo-инструмент, который поможет не только собрать качественное семантическое ядро, но и вычленить из всей массы запросов именно нужную объективную статистику без семантического мусора .
Определяем точную частотность запроса: уровень Pro
Давайте попробуем комбинировать операторы, и посмотрим, что из этого получится. Для примера возьмем новый запрос "купить машину". Базовая частотность 1 533 200 показа в месяц по всем регионам и устройствам.

Это очень широкий запрос, который включает в себя множество других подзапросов из разных ниш, например, "купить стиральную машину", "купить машину ауди", "купить посудомоечную машину". Как мы можем детализировать данные запросы? Допустим, нас интересуют стиральные машины.

Если мы хотим посмотреть точное количество запросов по ключевой фразе "купить стиральную машину", начинаем использовать операторы: кавычки и восклицательный знак. Получается 9257 показов в месяц. Заметьте, что количество показов в таблице осталось базовым.

Чтобы посмотреть этот же запрос, но при этом жестко фиксировать последовательность слов в нем, исключив, например, запросы "стиральную машину купить", "машину стиральную купить", добавляем оператор . Точное количество показов именно по этой фразе с сохранением формы и последовательности слов - 8903.

Заметьте, если мы изменим последовательность слов в нашем регулярном выражении, то мы получим совершенно другой результат показов - всего 308. Это вполне логично и интуитивно понятно, что количество людей, которые ищут стиральную машину с большей вероятностью будут строить свой запрос именно со слова "купить".

Но если мы изменим словоформу данного запроса, то, опять же, получим совершенно новый результат.

Вот так, например, можно зафиксировать предлог в запросе и добавить геозависимое слово. Учтите, что на скриншоте идет сбор статистики по всем регионам WordStats, а не только по Москве.

Идем дальше. Предположим, что вы продаете только стиральные машины без сопутствующих товаров. Запрос "купить стиральную машину" включает в себя множество подзапросов, среди которых "купить раковину для стиральной машины", "купить тэн для стиральной машины", "купить шланг для стиральной машины". Чтобы собрать нужную семантику, у вас уйдет уйма времени на проверку каждого запроса с помощью операторов " " и!. В данном случае нам поможет оператор "минус".

Таким образом, вы очищаете "мусорные" запросы в статистике, фильтруя только релевантные ключевые слова для вашего бизнеса .
Проверка частотности: 80 lvl
Переходим к более сложным тонкостям сбора статистики по запросам из Яндекса .
Пример #1
Начнем с оператора " " и сформулируем одно правило его использования: если во фразе, заключенной в кавычки, присутствуют одинаковые предлоги или слова, то одно из них заменяется на существующее слово во вложенном запросе . Для примера рассмотрим запрос "автомобиль в кредит москва".

Если добавить в данное ключевое слово еще один предлог "в" перед словом "москва", то получим следующие данные.

Таким образом повторяющиеся предлоги "в" были объединены, и к запросам добавилось еще одно слово. Для разных запросов это слова "купить", "бу", "новый", "залог", подержанные". "оформить".
Этот прием - невероятный инструмент для информационный сайтов, основной целью которых является рост трафика. Он позволяет выбрать из тематики весь диапазон запросов, которые включают в себя заданное количество слов, например, все запросы по тематике из 5 слов. Как правило, очень расширенные запросы из 5-7 слов бывают менее конкурентными, соответственно привлечь трафик и занять высокие позиции по ним легче. А если эти запросы не уступают в показах высокочастотным запросам? Выборка наиболее высокочастотных и наименее конкурентных запросов позволит вам быстро добиться результата. Давайте рассмотрим пример.

В данном запросе мы просим WordStat показать диапазон запросов, который включает в себя 7 слов, обязательно содержащих слова "инструкция по применения". 5 слов "инструкция" объединяются, остается одно, 4 слова заменяются на новые вложенные запросы. Смотрим один из сотен вложенных запросов, частотность запроса из 7 слов - 8090 показов в месяц. Для сравнению запрос "купить автомобиль в москве" имеет 647 показов в месяц. Разрыв шаблона еще не произошел? Тогда идем дальше.

Пример #2
Сейчас пойдет в бой более сложный оператор () и |, с его помощью мы соберем пул запросов, из которого в дальнейшем сможем сделать теговые страницы. Возьмем для примера запрос "купить автомобиль bmw". Данную марку авто, ее серии могут искать по самым разным запросам: "купить машину бмв", "купить bmw икс 6", "купить автомобиль бмв 5" и т.п. Для того чтобы получить пул запросов без повторений, используем регулярное выражение:
Купить (автомобиль|машина) (бмв|bmw) -пробегом -фото -не -заводится -скачать -бу -какая
Добавим в него сразу ряд нерелевантных минус-слов, которые не подходят для нашего бизнеса. Получаем следующие данные, которые впоследствие проще структурировать.

Данная выборка поможет вам проще собрать данные для теговых страниц и кластеризации данных.
Обратите внимание , нельзя в одном выражении использовать операторы " " и () |. Логика работы одного оператора нарушает логику работы другого .
Пример #3
Данный пример подойдет для быстрой структуризации информационных сайтов или сбора тегов для интернет-магазинов. Для примера возьмем информационный сайт о рыболовстве и попробуем быстро получить основные направления и места рыбалки с помощью группировки запросов по предлогам. Сделаем это простым регулярным выражением:
Рыбалка (+с|+на) -игра -бесплатная -скачать -русские -охота
Минус-слова, конечно же, нужно добавить, но в данном случае это просто пример. Получаем вот такой результат:

Пример #4
Совместное использование операторов поможет вам разграничить похожие по написанию, но разные по смыслу запросы. Например, запрос "купить тур в москвУ" подразумевает экскурсионную поезду в Москву.

Запрос "купить тур в москвЕ" подразумевает учет геопозиции пользователя для покупки тура из Москвы.

Пример #5
Еще один пример регулярного выражения, которое поможет вам собрать запросы для теговых страниц или фильтров каталога в нише купальников.

Даже если данные примеры не относятся к вашей нише, надеемся они помогут вам улучшить свои навыки работы с WordStat. Если у вас возникли вопросы, вы нашли ошибки, либо хотите дополнить статью, пожалуйста, пишите в комментарии, мы с радостью ответим вам!
У нас иногда спрашивают:
«Почему мой сайт в ТОПе по такому на первый взгляд «жирному» запросу как «металлоконструкции», но трафика на сайт с этого ключевика совсем мало. Какие-то 50-100 человек в месяц! Но ведь частотность у этого запроса огромная, аж 250 тысяч в месяц! Почему такое происходит?»
И правда, если вбить в wordstat.yandex.ru такой запрос, то частотность он нам покажет довольно внушительную:
При такой частотности позиция даже на 10 месте в выдаче должна приносить много трафика, но на деле все происходит совершенно иначе. В чем же причина? Давайте разбираться по порядку. Здесь есть несколько моментов, которые нужно учитывать. Начнем с самых простых и далее – по нарастающей.
Регион
Первое, про что все часто забывают, – это выбор региона при съеме частотности. Ни один коммерческий сайт не может продвигаться сразу по всем регионам, если он, конечно, не имеет офисы в каждом из них. Поэтому частотность снимается именно по тому региону, где находится офис компании. Если регионов несколько – отмечаем их все.
Например, компания, которая специализируется на поставках металлоконструкций и металлопроката, имеет офис в Москве, который добавлен в Яндекс.Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.

Иногда клиенты нам говорят:
«Я хочу продвигаться по всей России, мой интернет-магазин доставляет товар в любой регион».
И здесь мы вынуждены их разочаровать: к сожалению, даже внутри России интернет-магазин не может ранжироваться, если у него нет филиалов в соответствующих регионах. Под филиалами подразумевается привязанная в Яндекс.Справочнике карточка организации с подтвержденным офисом в регионе.Таким образом, при оценке спроса всегда нужно строго определять региональность.
Виды частотности
После выбора региона сразу видно, что частотность значительно уменьшилась.

Однако все равно это не реальные цифры конкретных фраз и, чтобы точно определить частотность каждого ключевика, нужно использовать специальный синтаксис.
Базовая частотность
Пока что мы собрали так называемую «Базовую частотность». Такой частотностью называют ту, которую мы получаем при вводе запроса в wordstat без какого-либо синтаксиса, выбрав регион или нет. Такая частотность представляет собой сумму частотностей всех фраз, где встречаются слова из запроса в любых словоформах и в любом порядке. Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.п.
Частотность в кавычках
Если мы хотим узнать частотность поискового запроса более точно, например, отсечь из нее те запросы, где присутствуют другие слова, то нужно брать запрос в кавычки. Иными словами, если вбить в wordstat запрос в таком виде – “металлоконструкции” – то получим следующую цифру:

Теперь мы видим, что отдельно слово «металлоконструкции» по Москве запрашивают в Яндексе только 948 человек. Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Частотность в кавычках и с восклицательным знаком (точная частотность)
Если задать запрос в wordstat в таком виде – “!металлоконструкции” – мы получим самую точную частотность. То есть будет отображаться частотность данного слова именно в таком виде, как мы написали:

В многословных запросах восклицательный знак нужно ставить перед каждым словом, так как данный оператор фиксирует словоформу каждого слова запроса по отдельности.
Таким образом, видна существенная разница в финальной частотности однословного запроса «металлоконструкции» по сравнению с изначальной базовой.
Точная частотность с учетом порядка слов
Однако, если мы подобным образом будем оценивать запрос, состоящий из двух слов, например, «купить металлоконструкции», то нужно еще учитывать порядок слов.
Так, например, если мы проверим точную частотность запросов: “!купить!металлоконструкции” и “!металлоконструкции!купить”, то обнаружим, что странным образом частотность у них будет одинаковая:

Это происходит по той причине, что операторы «кавычки» и «восклицательный знак» не учитывают порядок слов.Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить!металлоконструкции]”:

Таким образом, мы видим, что «купить металлоконструкции» ищут чаще, чем «металлоконструкции купить».
В результате мы разобрались, что основным фактором в оценке спроса по ключевым запросам, который обязательно нужно учитывать, является правильный съем частотности для семантического ядра. В качестве примера мы сравнили базовую и точную частотность для первых трех десятков фраз, которые выдает wordstat по запросу «металлоконструкции». В приведенной таблице в колонке «Показов в месяц» указана базовая частотность, которую выдал Яндекс без учета региона. В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».

Как видно, точная частотность значительно меньше базовой. Если исходить из такой методики оценки спроса, то картина, при которой позиция в ТОП-10 Яндекса по ключевой фразе «металлоконструкции», имеющей частотность 839, приносит 50-100 посетителей, уже выглядит более реальной.
Распределение кликабельности на первой странице выдачи
Но можно справедливо возразить:
Неужели при позиции в ТОП-10 с ключевика частотностью 839 будет всего лишь 50-100 посещений?
В общем-то да!
По разным оценкам распределение CTR в органической выдаче в ТОП-10 примерно такое:
- ТОП-1: 15-35%
- ТОП-2: 10-25%
- ТОП-3: 7-20%
- ТОП-4: 5-15%
- ТОП-5 – ТОП-10: 3-12%
Подсчеты, конечно, очень обобщенные, но примерно отражают актуальную картину: 3 или даже 4 блока контекстной рекламы забирают больше половины всего CTR. Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше. Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Оценка CTR через Яндекс.Директ
Наши слова легко проверить – достаточно зайти в Яндекс.Директ в прогноз бюджета и посмотреть там прогнозируемый CTR в зависимости от позиции в блоках контекстной рекламы на поиске.

Яндекс обычно слишком занижает показатели кликабельности в своих прогнозах, но это еще раз показывает, что даже высокая позиция по какому-либо запросу не гарантирует большого количества посетителей.
Заключение
В заключении подытожим, что для правильной оценки спроса и составления на ее основе стратегии поискового продвижения сайта важно собирать максимально полное семантическое ядро и правильно снимать частотность у всех фраз, а также задавать регион. Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
Эта статья рассчитана на новичков в SEO, а также на владельцев сайтов, которые выбрали себе запросы для продвижения, но не знают, частотные ли это запросы.
Итак, начнём.
Частотность запроса - это количество запросов или фраз, набранных пользователем в поисковой системе в определённый промежуток времени. Способы определения частотности запроса в поисковых системах отличаются. В этой статье мы рассмотрим частотность запросов в самых популярных поисковых системах - в Google и Яндексе.
Из этой статьи мы узнаем следующее:
1. Как определять частотность запросов в Яндексе
1.1. Сервис подбора слов в Яндексе
Для определения частоты запросов в Яндексе есть простой и удобный «Сервис подбора слов в Яндексе» или, как его ещё называют, Яндекс Wordstat .
Вбивая запрос в строку подбора, мы получаем следующую картину:

Примечательно, что сейчас мы видим общую картину по показам в месяц, но можно посмотреть частоту запроса отдельно по виду устройств (планшеты, мобильные телефоны, компьютеры), с которых пользователи искали запрос.

Так, мы видим, что 269 733 показа от общего количества пришлись на телефоны.
1.2. Виды частотности в Яндексе
Итак, мы узнали, что у запроса [пластиковые окна] было 1 006 660 показов в месяц - это будет базовая частота запроса.
Всего в Яндекс Wordstat выделяют три вида частоты:
- Базовая частота - обозначает число показов по всем запросам с нужным ключевым запросом. В нашем случае это запрос [пластиковые окна]. При сборе базовой частоты по этому запросу были учтены все возможные словоформы, а также варианты запросов [купить пластиковые окна], [цены на пластиковые окна] и т. д.
- Фразовая частота - для её определения нужно взять запрос в кавычки. Это позволит нам узнать частоту запроса по интересующей нас фразе.

Как видно по скриншоту, фразовая частота значительно ниже базовой, так как во фразовой частоте могут учитываться словоформы, падежи, разные окончания, но игнорируются добавочные слова (например, запрос [купить пластиковые окна] при сборе фразовой частоты не учитывается).
- Точная частота - для её определения нужно взять запрос в кавычки и перед каждым словом в запросе поставить восклицательный знак.

В таком виде мы узнаем количество показов в месяц конкретно по этому запросу.
1.3. Геозависимость
Помимо различной частоты запроса, мы можем узнать частоту по запросам в разных регионах. Для этого нужно вместо пункта «По словам» отметить пункт «По регионам».

На скриншоте видно общее число запросов, а также их количество конкретно по регионам. К примеру, в регионе «Москва» 13 847 показов, региональная популярность составляет 206%.
Что такое региональная популярность? Ответ Яндекса:
«Региональная популярность» - это доля, которую занимает регион в показах по данному слову, делённая на долю всех показов результатов поиска, пришедшихся на этот регион. Популярность слова/словосочетания, равная 100%, означает, что данное слово в данном регионе ничем не выделено. Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Также можно задать регион при сборе частоты. По умолчанию установлен сбор по всем регионам.
Выбираем регион.

Таким образом, при поиске точной частоты запроса по конкретному региону можно узнать, какое количество людей ищут интересующий вас запрос в указанном регионе.
1.4. Как определить сезонность запроса
В Яндекс Wordstat есть ещё одна интересующая нас функция. Для её использования нужно отметить пункт «История запросов».

Таким образом, мы видим, какой была частота запроса по месяцам в разные периоды. С помощью этой информации можно примерно спрогнозировать падения/подъёмы трафика на сайте.
1.5. Плагины для удобства пользования сервисом
Сервис Wordstat полезный, но не очень удобный, поэтому для того чтобы облегчить себе жизнь, при работе с ним я использую плагин Yandex Wordstat Assistant .
Вот так он выглядит в окне Вордстата:

Первое, что бросается в глаза, - это плюсы около запросов. Нажимая на них, мы добавляем запросы в колонку слева:

Это очень удобно, так как обычно нужно выделять каждый запрос и его частоту, чтобы его скопировать. Более того, можно спокойно переключаться на другие запросы, и список запросов, добавленных в колонку, сохранится.

Также этот плагин позволяет сортировать запросы прямо в колонке по частоте или алфавиту, а после - копировать эти запросы с частотой в нужный вам документ. Рекомендую использовать плагин для браузера Chrome, так как там более свежая версия, которая постоянно обновляется. Для FireFox тоже есть плагин, но он не обновлялся с апреля 2015 года, так что не все функции работают корректно.
2. Как определять частотность запросов в Google?
Если с Яндексом всё относительно просто, то узнать частоту запроса в Google будет сложнее. У Google нет сервиса вроде Яндекс Wordstat, поэтому приходится использовать сервис контекстной рекламы Google AdWords . Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Откройте вкладку меню «Инструменты» и в выпавшем меню найдите «Планировщик ключевых слов».

После этого откроется страница планировщика. На этой странице нужно выбрать «Получение статистики запросов и трендов». Там вбейте интересующий вас запрос и укажите регион.

Нажмите на кнопку «Узнать количество запросов». Вы получите такой результат:

Из-за ограничений AdWords у запроса среднее число запросов в месяц колеблется от 1000 до 10 000. Чтобы получить более подробную информацию, нужно создать и запустить кампанию.
При запущенной платной кампании частота запроса будет выглядеть следующим образом:

3. Программный сбор частоты запросов
Выше были описаны способы ручного сбора частоты запросов. При большом количестве запросов собирать их частоту вручную очень неудобно, поэтому я использую специальные программы.
3.1. Программа «Словоёб»
После настройки программы нужно запустить её и так же, как и в случае со «Словоёбом», добавить запросы, указать «Регион» и нажать на «Сбор статистики Yandex. Direct».

Key Collector, в отличие от «Словоёба», парсит данные, используя Яндекс. Директ, что значительно ускоряет процесс парсинга. Жмём «Получить данные» и получаем результат:

Программа позволяет собирать частоту и для Google, используя Google AdWords. Для этого нужно её настроить. Настройки можно посмотреть на официальном сайте Key Collector . Затем нужно будет нажать на кнопку «Сбор статистики Google. Adwords», которая находится рядом с кнопкой «Сбор статистики Yandex.Direct».
4. Онлайн-сбор частоты запросов
Иногда бывают ситуации, когда любимого инструмента нет под рукой, а частоту собрать нужно. В этом случае можно воспользоваться онлайн-сервисами для сбора частоты. Я рассмотрю 2 сервиса, которые использую сам. Один будет под Яндекс, другой - под Google.
4.1. Онлайн-инструмент для сбора частоты от SeoLib для Яндекса

Всё, что нужно сделать, - это открыть вкладку «Анализ ключевых фраз» и скопировать в форму для запросов или прикрепить отдельным файлом список интересующих запросов. После этого нужно выбрать необходимую частоту и регион, при необходимости указать дополнительные параметры. После нажать на «Начать анализ».
В форму нужно через запятую добавить ключевые слова и указать регион около кнопки «Пояса».
Результат:

Переходим во вкладку «Метрики»:

Итоги
Работа с Яндексом :
- Если запросов несколько, можно смотреть их вручную через Яндекс Wordstat. В таком случае я настоятельно рекомендую поставить плагин Yandex Wordstat Assistant - он заметно облегчает процесс;
- Если у вас есть список запросов и вам необходима быстрая разовая проверка, используйте онлайн-инструмент «Подбора ключевых слов» от SeoLib;
- Если вы постоянно работаете с запросами, рекомендую купить Key Collector. «Словоёб» хоть и бесплатный, но парсит слишком медленно, а время, которое вы сэкономите на парсинге запросов в Key Collector, с лихвой отобьёт затраты. «Словоёб» можно использовать, если вы работаете с небольшим списком запросов и пользуетесь им нечасто. Я сам им пользовался, когда начинал работу в SEO, но когда приобрёл Key Collector, пожалел, что не купил его раньше.
Работа с Google :
- Если запросов несколько, используйте Google AdWords;
- Если у вас есть список запросов, то удобнее будет воспользоваться онлайн-сервисом Ahrefs или настроить Key Collector.
Я перечислил сервисы, которые сам использую для сбора частоты запросов. Возможно, вы пользуетесь другими сервисами? Тогда укажите их в комментариях, буду рад ознакомиться с ними!
На этом пока всё, желаю вам хороших позиций по частотным запросам!
Подписаться на рассылкуЕсть несколько сервисов, позволяющих спрогнозировать частотность поисковых запросов , но большинство специалистов использует сервис от Яндекса - Яндекс Вордстат.
Отступление
У Яндекса существенная доля рынка (большая выборка данных) и удобный инструмент для анализа (Яндекс Вордстат). В инструменте от Mail вы можете получить более расширенные данные по каждому ключевому запросу, но на гораздо меньшей выборке данных. Сервис Яндекс Вордстат создавался в первую очередь для Яндекс Директа, но является очень полезным для seo-специалистов.
3 вида частотности запроса в Яндекс Вордстат
Ежедневно seo специалисты в своей работе используют 3 вида частотности. Вам необходимо уловить разницу и научиться правильно интерпретировать информацию, понять ее ценность.
Общая частость - это прогнозируемое количество показов в месяц введенной фразы с любым другими словами в любом падеже/склонение/числе и т.п. То есть, если вы введете запрос [доставка пиццы], то получите количество показов в месяц таких запросов, как: [доставка пиццы], [доставка пиццы круглосуточно], [недорогая доставка пиццы в Санкт-Петербурге в 3 часа ночи], [пицца ахтынзан доставка в Екатеринбург] и т.п.
Яндекс:Цифры рядом с каждым запросом в результатах подбора слов дают предварительный прогноз числа показов в месяц, которое вы получите, выбрав этот запрос в качестве ключевого слова. Так, цифра рядом со словом «телефон» обозначает число показов по всем запросам со словом «телефон»: «купить телефон», «сотовый телефон», «купить сотовый телефон», «купить новый сотовый телефон в крапинку» и т.п.
То есть Яндекс говорит нам, что слово «пицца» и любые словосочетания со словом «пицца» наберут 2 242 196 раз в месяц, а фразу «доставка пиццы» и все словосочетания с фразой «доставка пиццы» наберут 240 705 раз в месяц. С помощью этой информации можно найти интересные кластеры запросов, которые набирают пользователи и проанализировать потребности потенциальных клиентов. Например, здесь явно видно, что только 10% пользователей, которые искали что-либо связанное с пиццей, ищут ее доставку.
Часть пользователей хотят получать пиццу круглосуточно, а для другой части пользователей очень важно, чтобы пиццу привезли быстро. Это весьма ценная информация для вашего бизнеса, поэтому экспериментируйте и ищите интересные потребности в запросах.

2. Точная частотность запросов
Точная частость - это прогнозируемое количество показов в месяц введенной фразы без каких-либо других слов , но в любом падеже/склонение/числе и т.п. То есть, если вы введете запрос «доставка пиццы», то получите количество показов в месяц таких запросов, как: [доставка пицца], [пицца доставка], [доставка пицц] и т.п.
Чтобы получить точную частотность запроса, весь запрос необходимо взять в кавычки:

Точная частотность поможет найти ключевые запросы, которые реально набирают пользователи. Также обратите внимание, что только 6% пользователей , которые ищут что-либо с доставкой пиццы ограничиваются запросом [доставка пиццы], а 94% пользователей дополняют (конкретизируют) свой запрос.
3. Супер точная частотность запросов
Супер точная частость - это прогнозируемое количество показов в месяц введенной фразы без каких-либо других слов и в указанном падеже/склонение/числе и т.п. То есть, если вы введете запрос «!доставка!пиццы», то получите количество показов в месяц запроса [доставка пиццы].
Чтобы получить точную частотность запроса, весь запрос необходимо взять в кавычки и перед каждым словом поставить восклицательный знак:

Супер точная частотность позволяет выявить в каком падеже, числе и склонение люди набирают определенные запросы.
Предлоги в Яндексе
В вордстате не учитываются предлоги, когда вы анализируете общую частотность. Если вам нужно посмотреть ключевой запрос с предлогом, то перед предлогом необходимо поставить «+».
Прочувствуйте разницу:

Представьте, что вы хотите узнать сколько человек желает купить авиабилеты в Москву. Если вы наберете [авиабилеты в Москву], то получите 716 174 общей частотности, но в эту частотность входят и запросы [авиабилеты из Москвы], [авиабилеты Москва], [москва сочи авиабилеты] и другие.
Но если вы введете запрос [авиабилеты + в Москву], то увидите 66 841 общей частотности. Цифры отличаются в 10 раз, надеюсь, что вы не забудете указать «+»
В сервисе Яндекс Вордстат есть возможность проанализировать частотность запросов по необходимому региону. Иногда это бывает очень полезно.

В некоторых сферах деятельности вы сможете найти для себя подходящие запросы, которые встречаются только в определенных регионах. Например, названия географических объектов.
Также предусмотрен отдельный функционал, где вы сможете посмотреть популярность любого ключевого слова в разных регионах.

Сезонность (история запросов) - очень полезный функционал с помощью которого можно проанализировать частотность по ключевому слову в разные периоды времени. Данные хранятся за 2 года.
Например, вот так выглядит спрос на авиабилеты в Москву в разное время года:

Дополнительные операторы
Есть некоторые операторы, которыми пользуются квалифицированные специалисты. Если вы только начинаете осваивать поисковую оптимизацию, то не стоит фокусировать на них внимание.
Оператор «-»
Оператор «-» позволяет убрать ненужные слова (по аналогии с директом).


Оператор «|» (или)
Оператор «|» (или) позволяет получить результат сразу по нескольким условиям.

Оператор «()» (группировка)
Оператор «()» (группировка) позволяет комбинировать условия.
Всё, что нужно - почтовый аккаунт на Яндексе. Регистрация занимает всего пару минут.
Подбор ключевых фраз
По умолчанию Wordstat ищет по словам. Впишите в поиск ключевик и нажмите «Подобрать». Вы увидите разные запросы с данным словом и его словоформами.

Справа от каждого - частотность. Её значение основывается на данных за последние 30 дней и учитывает поиск в Яндексе.
Важные моменты по частотности:
- Она показывает не сколько раз вводят запрос строке поиска, а сколько раз выходит объявление Яндекс.Директ по этому запросу;
- Суммировать показы по всем вариантам - ошибка, так как они включены в общую сумму в первой строке;
- Показатели иногда накручены и не всегда отражают адекватный спрос. Причина - владельцы регулярно мониторят свои сайты. Также это работа сервисов по проверке позиций, накрутке поведенческих факторов, группировке поисковых запросов.
Вордстат предлагает фильтры по устройствам:
Сервис автоматически учитывает все падежи и числа и разбивает фразы на слова. Так, по запросу «галстук бабочка» выходит и «как завязывать галстук бабочку», и «купить бабочку галстук +в москве».
Wordstat также подбирает слова, которые пользователи вводили вместе с текущим запросом:

Если у вас моно-товар, который отличается по размеру, цвету, как в примере выше, правая колонка выдает различные вариации. Если запрос более обширный, как правило, это относится к сфере услуг, вы увидите несвязанные напрямую варианты. Например, выдача по фразе «Ремонт квартир»:

Это шанс выяснить:
- Как потенциальные клиенты стремятся решить проблему или удовлетворить потребность, и как они обращаются при этом к поисковику. Полезно это учитывать, когда основной ключевик не обеспечивает широкий охват;
- Дополнительные интересы аудитории (какие товары еще покупают, чем интересуются) для создания пользовательских персонажей;
- По каким фразам искать околоцелевой трафик, чтобы рекламироваться в РСЯ.
Если кликнуть на любую фразу, она появляется в строке поиска - и сервис выдает прогнозируемое число показов в месяц по ней.
Под результатами - переход на следующие страницы выдачи. К сожалению, нельзя попасть в конец по одному клику. Нужно перелистывать каждую страницу по кнопке «Далее».
Для суперпопулярных запросов сервис не показывает данные, расположенные дальше 40-й страницы. Например, по фразе «скачать торрент» свыше 32 миллионов запросов.
Выход - сторонние решения для парсинга. Самые популярные: Key Collector, YandexKeyParser, расширения Yandex Wordstat Helper и Yandex Wordstat Assistant (о них - в конце статьи).
Как уточнить запрос
Операторы помогают искать фразы по разным типам соответствия. Сравните количество показов:
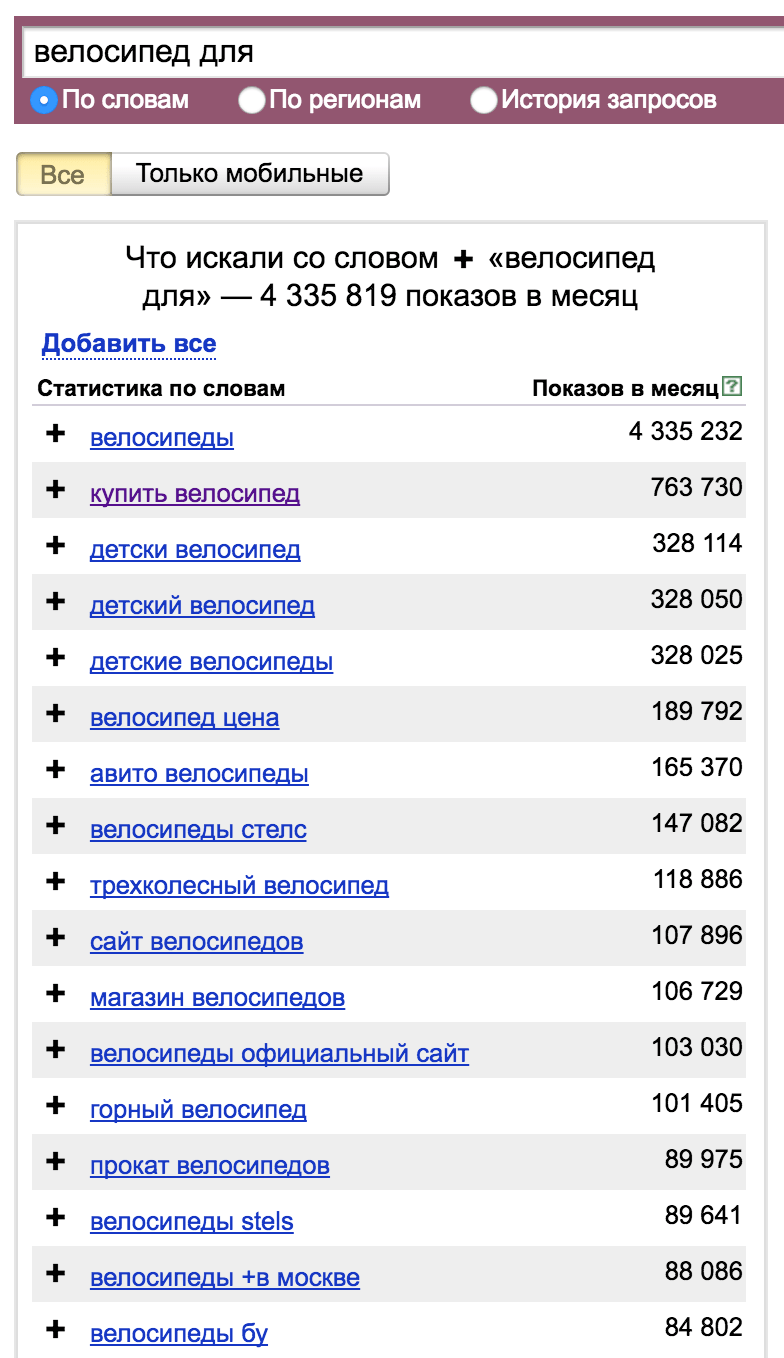
- Широкое - ремонт велосипедов - 10 519 показов в месяц;
- Фразовое - «ремонт велосипедов» - 631 показ в месяц;
- Точное (фиксация окончания) - «!ремонт!велосипедов» - 456 показов в месяц.
Для большей смысловой детализации результатов есть вспомогательный синтаксис:
- Минус исключает словосочетания, где есть это слово. Например, по запросу «галстук бабочка -детский» Wordstat не покажет словосочетания вроде «галстук бабочка детский купить», «детский галстук бабочка размеры».
- Плюс значит, что оно обязательно для выдачи. Особенно актуально для коротких предлогов и союзов, которые Яндекс иногда игнорирует. При вводе «известные ученые из россии», в списке видим и «самые известные ученые россии», и «известные ученые современной россии», и «известные женщины ученые россии». А для «известные ученые +из россии» получаем только то, что ищем.
- Восклицательный знак обеспечивает точное вхождение (сохранение числа и падежа, как в запросе).

- Оператор (|) добавляет синонимы. «Купить (одеяло|плед)» - это два запроса в одном: «Купить одеяло» и «Купить плед».

- Оператор фиксирует порядок слов в запросе. Сравните статистику и поймете, какой вариант чаще используют:

- Фиксированное число слов. Это пригодится для популярных тематик, когда сбор первых 40 страниц не позволяет получить все поисковые фразы. Варианта два:

Когда основной запрос двухсловный и нужны 4-словные варианты, пишем так:

Популярность запроса по регионам
Wordstat сортирует результаты по географии. Нажмите «Все регионы» и отметьте нужные:

Для четырех часто используемых вариантов есть опция «Быстрый выбор».
Галочка «по регионам» помогает оценить популярность запроса в конкретном регионе или городе. Более 100% - это повышенный интерес:

При необходимости можно посмотреть частоту использования слов на карте мира:

Определение сезонности запроса
Функция «История запросов» показывает динамику на основе данных за последние два года.
Выдача на большинство тематик зависит от сезона. Если в Вордстате нет нужной семантики, возможно, она появится в выдаче, когда наступит соответствующий сезон.
По запросам «новости» или «куда пойти» вы постоянно получаете разные списки.

По умолчанию выходят график и таблица по месяцам, но можно переключить на недели. В них - абсолютные (число показов по запросу) и относительные значения (его отношение к общему числу показов в Яндексе).

Еще одна фишка. По резким скачкам за короткий период можно выявить накрутку показов вебмастерами. Характерный признак - за отдельный короткий период фраза набирает тысячи, за остальные - 0.
Итак, теперь вы знаете, как получать семантику из Вордстата, с уточнением по значению, географии и сезонности. Далее рассмотрим, что с ними делать и как на примере. А именно - подберем СЯ из реальных данных сервиса.
Подбор семантического ядра
По оценкам экспертов, ручной парсинг в Wordstat дает 30-40% всех фраз. Но с учетом, что сервис бесплатный, это очень даже неплохо. Дополнительно можно генерировать ключевые слова по поисковым подсказкам и с помощью других инструментов.
Пример: спрос на деревянные окна.
Алгоритм
1) Определяем, как пользователи формулируют запрос. Открываем wordstat.yandex.ru и вбиваем фразу:

Результатов слишком много. Вручную их прорабатывать займет кучу времени. При этом среди них есть нерелевантные - «окна в деревянном доме», «деревянные наличники», «деревянные окна своими руками» и подобные.
Необходимо уточнить формулировку. Первым делом избавимся от «мусора» с помощью минус-слов: дом, наличники, своими руками, старые, жалюзи, как, утеплить, потеют.
2) Настраиваем регион - город Пермь - и тип устройств, с которых заходят потенциальные клиенты. Допустим, нас интересуют все пользователи, так как мы собираемся запускать кампании в мобайле и на десктопе:

3) Определяем целевой спрос. Для этого отбираем релевантные варианты из выдачи и заносим в таблицу Excel по разным сегментам.
В идеале нужно проработать все страницы, чтобы учесть все нюансы и составить более полную картину о потребностях целевой аудитории. Для простоты рассмотрим на примере первой:

На скриншоте серым цветом обозначены фразы, которые мы исключаем, так как они не подходят.
4) Просматриваем похожие фразы. Некоторые из них попадают в целевой спрос, например:

Можно также посмотреть второй столбец для подходящих слов, которые определили в пункте 3, и дополнить таблицу.
В итоге мы получаем определенное количество ключевых слов. Парсинга в Вордстате недостаточно. Семантическое ядро можно расширить с помощью более сложных платных и бесплатных инструментов. Кроме того, они автоматизируют дальнейшую работу с сервисом Wordstat.
Примеры:
- KeyCollector позволяет собирать СЯ, определять конкурентность, стоимость и эффективность ключевиков;
- Парсер ключевых слов «Магадан» (1 500 рублей, также предлагает бесплатную версию). Преимущество - удобный автоматический сбор, анализ и обработка статистики;
- AllSubmitter (модуль «подбор ключевых слов»).
Расширения для работы с Яндекс Wordstat
Вводить отдельные запросы для каждой фразы - это огромные затраты времени. Но от этого никуда не уйти. Зато есть решения, которые значительно упростят и ускорят работу с сервисом.
Yandex Wordstat Helper
Поддерживается Google Chrome и Mozilla Firefox. Помогает подбирать ключевики без бесконечных переключений между окнами и прочих неудобств, как в Excel или гугл-доках.
Bluetooth

