Вопросу, какая же СУБД - Postgresql или MS SQL для 1С является наиболее оптимальной, посвящено множество статей. В этой статье мы рассмотрим шаги оптимизации обоих. Каждая СУБД вендора имеет как собственные рекомендации по настройке, так и рекомендации фирмы 1С. Следует отметить, что в зависимости от оборудования, конфигурации серверов и количества пользователей, задающих разную нагрузку, детали процесса оптимизации СУБД под 1С и реализации рекомендаций могут меняться.
Настройка PostgreSQL под 1С
Опыт эксплуатации баз 1С на PostgreSQL показал, что наибольшей производительности и оптимальной работы 1С и PostgreSQL удалось добиться на linux, поэтому желательно использовать именно ее. Но вне зависимости от операционной системы, важно помнить, что настройки, указанные по умолчанию при установке PostgreSQL, предназначены только для запуска сервера СУБД. Ни о какой промышленной эксплуатации речи идти не может! Следующим шагом после запуска станет оптимизация PostgreSQL под 1С:
- Для начала отключаем Energy Saving (в противном случае могут непредсказуемо вырасти задержки ответов из БД) и запрещаем своппинг разделяемой памяти.
- Настраиваем основные параметры сервера СУБД (рекомендации по настройке описаны достаточно подробно, как на официальном сайте вендора, так и компанией 1С, поэтому остановимся только на самых важных).
- В типовых рекомендациях компании 1С предлагается отключать механизмы HyperThreading. Но тестирование Postgres-pro на серверах, с включенной SMT (simultaneous multi threading), показало другие результаты .
Установка PostgreSQL
Установка 1С на PostgreSQL под Windows – достаточно простой процесс. При запуске установочного пакета необходимо указать кодировку UTF-8. По сути, это единственный интересный нюанс и еще какая-то настройка PostgreSQL для 1С 8.3 из-под Windows не потребуется. Установка и настройка PostgreSQL для 1С на ОС linux может вызвать ряд затруднений. Для их преодоления в качестве примера рассмотрим запуск работы (используя дистрибутивы ведущего российского вендора PostgreSQL-Pro и компании 1С) PostgreSQL на сервере Ubuntu 16.04 х64
Установка дистрибутивов 1С для СУБД PostgreSQL
1.Скачиваем указанную позицию дистрибутива СУБД PostgreSQL:
2.Выкладываем PostgreSQL на сервер;
3.Распаковать установщик СУБД PostgreSQL можно командой:
tar -xvf postgresql-9.4.2-1.1C_amd64_deb.tar.bz24.Перед установкой дистрибутива СУБД PostgreSQL проверим наличие в системе необходимой локали (по умолчанию ru_RU.UTF-8):

5.Если система, с которой будет работать PostgreSQL, ставилась с языком отличным от русского, необходимо создать новые локали:
locale-gen ru_RU update-locale LANG=ru_RU.UTF8 dpkg-reconfigure locales6.Если необходимая локаль все же имеется, устанавливаем ее по умолчанию:
locale –a nano /etc/default/locale Заменяем содержимое на LANG=ru_RU.UTF-87.После перезагрузки, установим необходимые пакеты для нашей версии PostgreSQL:
apt-get install libxslt1.1 ssl-cert8.Версия PostgreSQL пакета 9.4.2-1.1C связана с пакетом libicu версии libicu48. В репозитории нужной версии уже нет, ее можно скачать ;
9.Скачиваем и помещаем в каталог, где хранятся скачанные файлы для PostgreSQL;
10.Перейдя в каталог с файлами PostgreSQL, производим установку, последовательно набирая следующие команды:
cd <Путь к папке с файлами> dpkg -i libicu48_4.8.1.1-3ubuntu0.6_amd64.deb dpkg -i libpq5_9.4.2-1.1C_amd64.deb dpkg -i postgresql-client-common_154.1.1C_all.deb dpkg -i postgresql-common_154.1.1C_all.deb dpkg -i postgresql-client-9.4_9.4.2-1.1C_amd64.deb dpkg -i postgresql-9.4_9.4.2-1.1C_amd64.deb dpkg -i postgresql-contrib-9.4_9.4.2-1.1C_amd64.deb11.Готово. Дистрибутив СУБД PostgreSQL установлен.
Установка дистрибутивов PostgreSQL-Pro
Для установки сервера необходимо выполнить подряд следующие команды:
sudo sh -c "echo "deb http:// 1c.postgrespro.ru/deb/ $(lsb_release -cs) main" > /etc/apt/sources.list.d/postgrespro-1c.list" wget --quiet -O - http:// 1c.postgrespro.ru/keys/GPG-KEY-POSTGRESPRO-1C-92 | sudo apt-key add - && sudo apt-get update sudo apt-get install postgresql-pro-1c-9.4Для доступа к серверу редактируем параметры в файле pg_hba.conf
сd <Путь до каталога pg_hba.conf> cp pg_hba.conf pg_hba.conf.old bash -c "echo "local all postgres trust" > pg_hba.conf" bash -c "echo "host all all all md5" >> pg_hba.conf"Сам файл имеет следующую структуру:

Файл хорошо документирован, но на английском языке. Кратко рассмотрим основные параметры:
- Local локальное подключение только через unix
- Host подключение по TCP/IP
- Hostssl шифрованное SSL-подключение по TCP/IP (сервер должен быть собран с поддержкой SSL, также требуется установить параметр ssl)
- Hostnossl нешифрованное подключение по TCP/IP
- trust допустить без аутентификации
- reject отказать без аутентификации
- password запрос пароля открытым текстом
- md5 запрос пароля в виде MD5
- ldap проверка имени и пароля с помощью сервера LDAP
- radius проверка имени и пароля с помощью сервера RADIUS
- pam проверка имени и пароля с помощью службы подключаемых модулей
Более подробную и развернутую информацию можно посмотреть в документации к продукту PostgreSQL.
root@NODE2:/home/asd# service --status-all |grep postgres [ - ] postgresql root@NODE2:/home/asd# service postgresql start root@NODE2:/home/asd# service --status-all |grep postgres [ + ] postgresqlПосле окончания основной установки, необходимо настроить конфигурационный файл сервера postgresql.conf, согласно специфики работы PostgreSQL, сервера 1С и конфигурации сервера Ubuntu.
Оптимизация 1С под MS SQL Server
Устанавливаем последние обновления для SQL Sever.
Операционная система резервирует место и забивает его нулями, что занимает достаточно много времени при следующих событиях:
- Создание базы данных;
- Добавление файлов данных, журнал транзакций, к существующей базе данных;
- Увеличение размера существующего файла (в том числе Autogrow-операций);
- Восстанавливаем базы данных или группы файлов.
Решается данная проблема добавлением роли (под которой запущен сервер) к пункту локальной политики безопасности «Выполнение задач по обслуживанию томов».
При возможности необходимо разнести базу TempDB (особенно интенсивно она используется в режиме управляемых блокировок RCSI) и журнал транзакций на разные диски.
На сервере, где работает SQL сервер, режим энергосбережения должен быть установлен в «Высокая производительность».
В папке с файлами БД не должно быть сжатия.
На вкладке «Память» для сервера устанавливаем минимальную планку в размере 50% от общего объема памяти. Максимальную рассчитываем по одной из формул:
- Максимальная память = Общий объем – размер по ОС – размер под 1С (Если он есть, предварительно замерив счетчиками используемую память) или
- Максимальная память = Общий объем – (1024* Общий объем/16384).
Ограничиваем параметр DOP «Max degree of parallelism» и ставим его в значение «1».
Актуализируем статистику по расписанию. Начиная с SQL Server 2008, обновление статистики вызывает перекомпиляцию запросов и, соответственно, очищает процедурный кэш, поэтому отдельную процедуру по очистке процедурного кэша выполнять не надо.
Периодически проводим реиндексацию таблицы и дефрагментацию индексов.
Устанавливаем правильную политику резервирования. Если вам не надо восстанавливаться на последний момент времени к краху системы, а последние минут 5 или больше для вашего бизнеса не критичны, то установите модель восстановления в «Простая». Этим вы ускорите в разы скорость при записи. Главное, чтобы дифференцированный бекап успевал выполняться за указанное время.
Добиваемся улучшения при работе с TempDB при вводе/выводе посредством создания дополнительных файлов данных. Если логических процессоров меньше 8, рекомендуется создать файл данных для каждого логического процессора. Если логических процессоров больше 8, рекомендуется создать 8 файлов данных и, увеличивая на один при кратности 4, обязательно оценить нагрузку на TempDB.
В этой статье мы постараемся рассказать, как самостоятельно выполнить публикацию базы данных на сервере, как связать PosgreSQL и 1С и какие подводные камни могут встретиться на вашем пути.
Для чего это надо
Использование позволяет:
- Снизить системные требования к компьютерам пользователей, за счет перераспределения нагрузки;
- Работать с базами данных больших объемов;
- Использовать тонкий клиент для работы с информацией;
- Оптимизировать время выполнения запросов и обращений к базе данных;
- Автоматизировать выполнение фоновых и регламентных заданий;
- Настроить резервное копирование и ускорить время восстановления базы данных из сохраненной копии.
Условия для решения задачи
На старте мы имеем:
- Персональный компьютер с установленной 64 разрядной операционной системой Windows 7;
- Инсталлятор 1С, платформа 8.3.10.2505;
- Файловую базу данных «Зарплата и управление персоналом», версия 3.1.3.223;
- Оптимизированный для 1С postgreSQL установщик PostgreSQL 64-bit 9.4.11;
- Дополнительную утилиту для администрирования сервера pgAdmin 4.
Приступим к установке.
Установка сервера и его настройка
В нашу задачу не входит вопрос о тонкостях настройки PostgreSQL сервера и каких-либо его нюансах. Мы постараемся максимально просто и доступно рассказать, как подружить его с 1С. Исходя из вышесказанного, мы не будем менять параметры, автоматически выдаваемые инсталлятором.
Дойдя до окна (Рис.1) мы должны будем ввести пароль супер пользователя.
Если Вы настраиваете рабочий сервер, одной из задач которого будет являться защита данных и организация стороннего доступа к ним, то помимо пароля следует так же изменить имя главного пользователя сервера.
Галочка «Поддерживать подключение…» установлена по умолчанию, в случае, если сервер базы данных и сервер 1С находятся на одном компьютере, ее можно снять.
Так как на подопытном компьютере установлена только одна 4GB плитка оперативной памяти, программа автоматически может увеличить её объем, о чем и сообщает окно (Рис.2).
 Рис. 2
Рис. 2
В принципе, больше здесь настраивать нечего. После установки в главном меню появится соответствующая папка (Рис.3).
 Рис. 3
Рис. 3
Отсюда можно останавливать, перезагружать и стартовать сервер.
Ее установка также не представляет никаких проблем.
Выполняем её запуск и видим окно (Рис.4)
 Рис.4
Рис.4
Дальнейшая последовательность действий:

На этом подготовка PostgreSQL к работе вроде бы закончена, но что делать, если наш сервер должен обслуживать несколько различных баз данных? Как физически разделить места их хранения?
Для этого необходимо вызвать контекстное меню ветки «Tablespaces» и создать новый элемент. Для каждой базы данных можно прописать:
- Имя места хранения;
- Месторасположение рабочей директории;
- Создать комментарий, содержащий подробную информацию о месторасположении таблиц.
Теперь приступим к настройке 1С.
Установка и настройка 1С
Запускаем инсталлятор платформы и устанавливаем следующие компоненты:
- Сервер 1С Предприятия;
- Утилиту администрирования сервера;
- Модули расширения сервера;
- Саму платформу.
Это обязательный набор, остальные компоненты устанавливаются по желанию (Рис.9).
 Рис.9
Рис.9
На втором шаге нам предложат выбрать пользователя или создать нового (Рис.10).
 Рис.10
Рис.10
В случае, если мы собираемся использовать текущего или другого, отличного от USR1CV8, пользователя, мы должны ему добавить следующие права:
- Вход в систему как сервис;
- Вход в систему как пакетное задание.
Запустив утилиту администрирования, убеждаемся, что наш сервер активен.
Добавляем новую информационную базу в дерево администрирования (Рис.11)
 Рис.11
Рис.11
Здесь важно отметить, что создание базы данных 1С на PostgreSQL сервере можно выполнить и из окна запуска приложения. В этом случае:

Чуть подробнее про эту форму:
- Кластер серверов – если база находится на том же компьютере, что и сервер, в качестве значения здесь будет использована строка «localhost»;
- Имя базы в кластере – именно под этим именем администратор сервера будет видеть информационную базу в дереве кластера;
- Тип СУБД – так как мы поднимаем PostgreSQL cервер, именно его и надо указать в окне;
- Имя базы данных – это для идентификации базы в утилите администрирования PostgreSQL сервера;
- Пользователь – суперюзер указанный при создании сервера;
- Пароль – соответственно пароль суперюзера.
Таким образом, мы создали пустую информационную базу 1С на сервере PostgreSQL. Чтобы начать с ней работать, достаточно в режиме «Конфигуратор» загрузить выгруженную из файлового варианта копию базы (в формате dt).
Для того, чтобы с нашей базой данных можно было работать с удаленного компьютера, в настройках файервола открыть соответствующие порты.
1 Ноя 2012 Преимущества использования свободно распространяемого программного обеспечения очевидны. К сожалению, очевидны и недостатки - нет официальной поддержки, зачастую документация противоречива, неполна и разбросана по разным источникам. Эта статья поможет разобраться с процессом установки PosgreSQL для "1С:Предприятие 8", избежав подводные камни, которые не описаны в официальной документации.
Необходимые компоненты для установки
СУБД PostgreSQL распространяется бесплатно и входит в комплект поставки сервера приложений "1С". Сервер приложений "1С:Предприятие 8" поставляется в двух вариантах: 32-разрядный и 64-разрядный. Postgre может работать с обоими.
Итак, имеем на руках дистрибутивы:
- Postgre: postgresql-9_1_2-1_1Cx64.zip, любезно предоставленный фирмой "1С".
- Дистрибутив сервера приложений "1С:Предприятие" для Windows x64, версии 8.2.16.368.
Казалось бы, чего проще - запусти и установится. Легко! Но установка в стандартном режиме даст одно небольшое ограничение: кластер у нас будут лежать в папке "Program Files". Не всем это понравится. Рассмотрим два варианта установки, простой и расширенный.
Статья разбита на 5 разделов:
1) Установка сервера 1C.
2) Установка PostgreSQL в стандартном виде, достаточном для запуска 1С без дополнительных настроек.
3) Установка PostgreSQL с выбором папки хранения кластера.
4) Создание новой информационной базы 1С.
5) Указание папки хранения файлов базы данных на сервере СУБД.
Перед установкой обязательно прочитайте всю статью целиком!
Установка сервера приложений 1С
Запускаем setup.exe из папки с дистрибутивом сервера 1С.


В том случае, если вы установите сервер приложений не как сервис, нужно будет вручную его запускать каждый раз. Требуется такой вариант редко. Устанавливаем как службу (сервис), и решаем, под каким пользователем он будет запускаться. Из соображений безопасности лучше создать отдельного пользователя USR1CV82, а не разрешать сервису работать под полными правами.
После установки сервера приложений система предложит установить драйвер ключа защиты HASP. Соглашаемся:

Дожидаемся сообщения:

Если сообщение будет другим, в системе, скорее всего, остались "хвосты" от предыдущих установок драйверов HASP. Удаляйте их все, и пробуйте заново.

Готово, сервер приложений "1С:Предприятие 8" мы установили успешно.
Установка PostgreSQL в стандартном виде, достаточном для запуска 1С без дополнительных настроек
Запускаем "postgresql-9.1.2-1.1C(x64).msi"



Опции установки можно не менять, 1С работать будет. Далее.

Postgre, как и сервер 1С, может сам создать пользователя, под которым будете запускаться служба. Обращаю ваше внимание на то, что если указать учетную запись с правами администратора, то служба корректно работать не будет. Обязательно создавайте нового пользователя.

Следующее окно установки.

Инициализируем кластер. Если у нас сервер баз данных и сервер приложений 1С находятся на разных компьютерах, тогда устанавливаем галочку «Поодерживать подсоединения с любых IP», иначе не трогаем. Обязательно указываем кодировку UTF8. Создаем суперпользователя СУБД. Далее…




Для начальной работы нам ничего дополнительного не нужно, снимаем галочку, завершаем установку.
Результат наших усилий - готовый к работе PostgreSQL. Если нас устраивает, что базы будут лежать в Program Files\PostgreSQL\9.1.2-1.1C\data - заканчиваем на этом, раскрываем базы и наслаждаемся процессом. Однако, чаще все-таки базы данных "лежат" на специально предназначенных для этого дисковых массивах, а не на системном диске. Для того, чтобы настроить расположение данных, перед установкой прочитайте следующий раздел.
Установка Postgre с выбором места хранения кластера
Приступаем к установки Postgre и выполняем все шаги до тех пор, пока нам не предложат инициализировать кластер:

Снимаем галочку "Инициализировать кластер базы данных" и нажимаем "Далее".

Да, уверены.

Снимаем галочку "По выходу запустить Stack Builder" и завершаем установку.
1. Необходимо выдать полные права на папку в которую мы установили PostgreSQL, обычно это C:\Program Files\PostgreSQL
2. Из под админских прав запускаем cmd. Если это делаете в win7, то запускаем от Администратора.
3. Создаем папку где будет храниться кластер. Например d:\postgredata.
md d:\postgredata
4. Проводим инициализацию кластера вручную с указанием пути где он будет находиться.
“C:\Program Files\PostgreSQL\9.1.2-1.1C\bin\initdb.exe” -D d:\postgredata --locale=Russian_Russia --encoding=UTF8 -U postgres
5. Удаляем службу PostgreSQL, которая была установлена в ходе установки.
sc delete pgsql-9.1.2-1.1C-x64
Где pgsql-9.1.2-1.1C-x64 - Это название службы. Если не знаете название точно, можно посмотреть свойствах службы “PostgreSQL Database Server…” (Пуск – Панель управления – Администрирование – Службы)
6. Создаем новый сервис с указанием нашего кластера
“C:\Program Files\PostgreSQL\9.1.2-1.1C\bin\pg_ctl” register -N pgsql -U postgresql -P пароль -D d:/postgredata
7. Теперь заходим в службы. Пуск – Панель управления – Администрирование – Службы и стартуем нашу службу.
Создание новой базы данных 1С на сервере с PostgreSQL
Есть несколько вариантов создания базы данных. Можно попробовать создавать базу через pgAdmin3, консоль администрирования серверов 1С. Но тут вы столкнетесь с массой непонятных вопросов и кучей ошибок, ответы на которые будете долго искать. Оставьте это для специалистов. Наша задача получить работоспособную базу с минимальными усилиями. Опишем самый простой путь добиться этого.
Запускаем клиент 1С.

Нажимаем "Добавить...".



Придумываем название базы, указываем "На сервере 1С:Предприятия", далее.

Кластер серверов 1С:Предприятия – localhost, если мы создаем базу на том же компьютере, где установлен сервер 1С, или имя сервера приложений 1С, если на другом.
Имя информационной базы в кластере - в дальнейшем это название будет указываться при подключении с других компьютеров.
Тип СУБД – Выбираем PostgreSQL.
Сервер баз данных - указываем название сервера PostgreSQL. Если создаем базу на сервере, так же указываем localhost.
Имя базы данных – с таким название будет создана база в PostgreSQL.
Пользователь, пароль – имя пользователя, которого мы указывали как суперпользователя при установке PostgreSQL. Обязательно поднимаем галочку "Создать базу данных в случае ее отсутствия".
Возникает вопрос - а где база будет храниться физически? В папке Base указанного кластера. А если мы не хотим, чтоб она лежала там, где лежат все базы? Тут пока ничего поделать нельзя, просто создаем базу и двигаемся дальше. Далее…

Указание папки хранения базы данных
Итак, мы создали базу. В большинстве случаев на этом установка заканчивается. Однако, если баз много, и есть несколько дисковых массивов для разных групп баз, нужно указать, где физически должны располагаться базы. Чтобы сделать это, запускаем pgAdmin3 из Пуск – Программы – PostgreSQL. Подключаемся к нашему серверу.

При первом подключении Postgre попросит пароль для пользователя postgres (которого мы создавали при установке).


Создаем новый TableSpace, это будет та папка, в которой будут храниться наши базы.

Указали место хранения файлов базы. Ок.

Теперь открываем свойства уже созданной ранее базы данных, размещение которой мы хотим изменить.

Меняем свойство Tablespace. После нажатия "ОК" файлы базы данных будут автоматически перемещены. Готово! Надеемся, что статья была вам полезна. Если это так - оставляйте комментарии, делитесь ссылками на эту страницу. Спасибо!
Ниже указанные настройки не панацея, их надо корректировать с учетом реальных доступных мощностей. Реального количества пользователей и интенсивности (записываемой) ввода информации. При настройках системы также важно насколько профессионален тот, кто настраивает ее.Какую ОС установить:
Процессор
autovacuum_max_workers = NCores/4..2 но не меньше 4Количество процессов автовакуума. Общее правило — чем больше write-запросов, тем больше процессов. На read-only базе данных достаточно одного процесса.
Ssl = off
Выключение шифрования. Для защищенных ЦОД’ов шифрование бессмысленно, но приводит к увеличению загрузки CPU
Память
shared_buffers = RAM/4Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL. Операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память.
Temp_buffers = 256MB
Максимальное количество страниц для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии.
Work_mem = RAM/32..64 или 32MB..128MB
Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется оптимайзером: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает экзекьютору сразу создать временную таблицу. work_mem не является в полном смысле лимитом: оптимайзер может и промахнуться, и запрос займёт больше памяти, возможно в разы. Это значение можно уменьшать, следя за количеством создаваемых временных файлов:
Maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB
Лимит памяти для обслуживающих задач, например по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске.
Effective_cache_size = RAM - shared_buffers
Оценка размера кеша файловой системы. Увеличение параметра увеличивает склонность системы выбирать IndexScan планы. И это хорошо.
Диски
effective_io_concurrency = 2 (только для Linux систем, не применять для Windows)Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Для одиночного диска = 1, для RAID — 2 или больше.
Random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для
Стоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
Seq_page_cost = 0.1 для NVMe дисков autovacuum = on
Включение автовакуума.
Autovacuum_naptime = 20s
Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать вакуумиться и, как следствие, вырастет bloat и размер таблиц и индексов. Малая величина приведет к бесполезному нагреванию.
Bgwriter_delay = 20ms
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
Bgwriter_lru_multiplier = 4.0 bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чемbgwriter_lru_maxpages.
Synchronous_commit = off
Выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
Checkpoint_segments = 32..256 < 9.5
Максимальное количество сегментов WAL между checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему по записи. Каждый сегмент имеет размер 16MB
Checkpoint_completion_target = 0.5..0.9
Степень «размазывания» checkpoint’a. Скорость записи во время checkpoint’а регулируется так, что бы время checkpoint’а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_ target.
Min_wal_size = 512MB .. 4G > =9.5 max_wal_size = 2 * min_wal_size > =9.5
Минимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments
Fsync = on
Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания. Внимание: если RAID имеет кеш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кеша RAID контроллера! Иначе данные записанные в кеш RAID могут быть потеряны при выключении питания, и, как следствие, PgSQL не гарантирует целостность данных.
Commit_delay = 1000
паузу (в микросекундах) перед собственно выполнением сохранения WAL
Commit_siblings = 5
Минимальное число одновременно открытых транзакций, при котором будет добавляться задержка commit_delay
Групповой коммит нескольких транзакций. Имеет смысл включать, если темп транзакций превосходит 1000 TPS. Иначе эффекта не имеет.
Temp_tablespaces = "NAME_OF_TABLESPACE"
Дисковое пространство для временных таблиц/индексов. Помещение временных таблиц/индексов на отдельные диски может увеличить производительность. Предварительно надо создать tablespace командой CREATE TABLESPACE. Если характеристики дисков отличаются от основных дисков, то следует в команде указать соответствующий random_page_ cost. См. .
row_security = off >= 9.5
Отключение контроля разрешения уровня записи
Max_files_per_process = 1000 (default)
Максимальное количество открытых файлов на один процесс PostreSQL. Один файл это как минимум либо индекс либо таблица, но таблица/может состоять из нескольких файлов. Если PostgreSQL упирается в этот лимит, он начинает открывать/закрывать файлы, что может сказываться на производительности. Диагностировать проблему под Linux можно с помощью команды lsof.
Сеть
max_connections = 500..1000Количество одновременных коннектов/сессий
Если у Вас больше 100 пользователей, то лучше указать вручную значение для этого параметра по количеству пользователей
Типовая проблема в Windows
Ошибка СУБД: could not send data to server: No buffer space available (0x00002747/10055)
При использовании операционной системы Windows, максимальное стандартное число временных TCP-портов равно 5000. При попытке установить TCP-соединение через порты, номера которых превышают 5000, выдается сообщение об ошибке. Другими словами, надо увеличить количество доступных портов в реестре, где выберите Parameters (HKEY_LOCAL_MACHINE\SYSTEM\ CurrentControlSet\Services\ Tcpip\Parameters) и добавьте следующий параметр реестра MaxUserPort с типом: DWORD и значением: 65534 (Допустимые значения: 5000-65534)
Блокировки
max_locks_per_transaction = 256Максимальное число блокировок индексов/таблиц в одной транзакции
Настройки под платформу 1С
standard_conforming_strings = offРазрешить использовать символ \ для экранирования
Escape_string_warning = off
Не выдавать предупреждение о использовании символа \ для экранирования
Shared_preload_libraries = "online_analyze, plantuner"
несколько разделяемых библиотек, которые будут загружаться при запуске сервера
если указанная в нём библиотека не будет найдена, сервер не запустится
настройка параметра имеет больше значения для linux, хотя и windows её делать тоже стоит
Модуль online_analyze предоставляет набор функций, которые немедленно обновляют статистику после операций INSERT, UPDATE, DELETE или SELECT INTO в целевых таблицах.
Модуль plantuner добавляет поддержку указаний для планировщика, позволяющих отключать или подключать определённые индексы при выполнении запроса.
Online_analyze.enable = on
Включает анализ статистики временных таблиц, часто используемых в 1С
Оптимизатор
default_statistics_target = 1000 -10000(Улучшение статистики оптимизатора)
Enable_nestloop=off, enable_mergejoin=off
(Изменение параметров оптимизатора)
● Включает или отключает использование планировщиком планов соединения с вложенными циклами
● Включает или отключает использование планов соединения слиянием.
Например ошибки типа out of memory
Join_collapse_limit=1
(отключение при понимании порядка соединений таблиц!)
● При значении, равном 1, предложения JOIN переставляться не будут, так что явно заданный в запросе порядок
соединений определит фактический порядок, в котором будут соединяться отношения.
Прочие настройки влияющие на оптимизатор
From_collapse_limit = 20
● Задаёт максимальное количество элементов в списке FROM, до достижения которого планировщик будет сносить в него явные конструкции JOIN (за исключением FULL JOIN). При меньших значениях сокращается время планирования, но план запроса может стать менее эффективным.
● seq_page_cost = 0.1 random_page_cost = 0.4 cpu_operator_cost = 0.00025
Online_analyze.table_type = "all"
(больше нагрузка)
Типы таблиц, для которых выполняется немедленный анализ: all (все), persistent (постоянные), temporary (временные), none (никакие).
Online_analyze.threshold = 50
● Минимальное число изменений строк, после которого может начаться немедленный анализ (этот параметр подобен autovacuum_analyze_threshold).
Online_analyze.scale_factor = 0.1
Процент от размера таблицы, при котором начинается немедленный анализ (этот параметр подобен autovacuum_analyze_scale_factor).
Online_analyze.min_interval = 10000
● Минимальный интервал времени между вызовами ANALYZE для отдельной таблицы (в миллисекундах).
Online_analyze.local_tracking = off
● Включает в online_analyze отслеживание временных таблиц в рамках обслуживающего процесса. Когда эта переменная отключена (off), online_analyze использует для временных таблиц системную статистику по умолчанию.
Online_analyze.verbose = "off"
● Отключает подробные сообщения расширения online_analyze
Plantuner.fix_empty_table = "on"
● plantuner будет обнулять число страниц/кортежей в таблице, которая не содержит никаких блоков в файле
Вариант использования в качестве сервера баз данных PostgreSQL на windows платформе не очень популярен, но имеет место быть как правило, когда необходимо хоть как-то сэкономить на продуктах от MS. Так же существуют специализированные приложения, которые наилучшим образом работают с PostgreSQL. Для 1с существует модифицированная сборка PostgreSQL дающая как уверяют разработчики сопоставимый с MSSQL уровень производительности и отказоустойчивости. Так ли это на самом деле, проверим на практике:)
1. Установка PostgreSQL
Качаем с сайта 1с последнюю сборку PostgreSQL 64-bit 9.1.2-1.1C, распаковываем архив, запускаем msi-пакет, тот что без int, имеет не большой размер файла.
 Нажимаем Start.
Нажимаем Start. Опции установки оставляем по умолчанию.
Опции установки оставляем по умолчанию.
 Задаем пароль пользователю postgres
от которого будет стартовать сервис.
Нажимаем Далее. Если установка PostgreSQL производится впервые, то мастер предложит создать пользователя postgres.
Задаем пароль пользователю postgres
от которого будет стартовать сервис.
Нажимаем Далее. Если установка PostgreSQL производится впервые, то мастер предложит создать пользователя postgres.
 На этапе инициализации БД, выбираем кодировку UTF8. Задаем логин и пароль внутреннему пользователю postgres. Внимание! Пароли пользователя сервиса PostgreSQL и пароль внутреннего пользователя БД PostgreSQL не должны совпадать. Пароль должен состоять как минимум из четырех символов. Если сервер 1C и PostgreSQL планируется запускать на разных машинах, то необходимо поставить галочку «Поддерживать соединения с любых IP, а не только с localhost». Нажимаем Далее и еще раз Далее. :)
На этапе инициализации БД, выбираем кодировку UTF8. Задаем логин и пароль внутреннему пользователю postgres. Внимание! Пароли пользователя сервиса PostgreSQL и пароль внутреннего пользователя БД PostgreSQL не должны совпадать. Пароль должен состоять как минимум из четырех символов. Если сервер 1C и PostgreSQL планируется запускать на разных машинах, то необходимо поставить галочку «Поддерживать соединения с любых IP, а не только с localhost». Нажимаем Далее и еще раз Далее. :)
 Нажимаем еще два раза Далее и дожидаемся окончания установки.
Нажимаем еще два раза Далее и дожидаемся окончания установки.
 Затем идем в Start\All Programs\PostgreSQL 9.1.2-1.1C(x64). Запускаем утилиту администрирования pgAdmin III. Пробуем подключится к БД. Вводим пароль, который указывали во время установки.
Затем идем в Start\All Programs\PostgreSQL 9.1.2-1.1C(x64). Запускаем утилиту администрирования pgAdmin III. Пробуем подключится к БД. Вводим пароль, который указывали во время установки. И получаем следующую ошибку: Error connecting to the server: FATAL: password authentication failed for user «postgres».
И получаем следующую ошибку: Error connecting to the server: FATAL: password authentication failed for user «postgres».
 Довольно неожиданно, с учетом того, что пароль был набран верно. Решил поковырять pg_hba.conf, но на первый взгляд там все хорошо.
Довольно неожиданно, с учетом того, что пароль был набран верно. Решил поковырять pg_hba.conf, но на первый взгляд там все хорошо.
# TYPE DATABASE USER ADDRESS METHOD # IPv4 local connections: host all postgres::1/128 md5 host all postgres 127.0.0.1/32 md5 host all postgres 192.168.1.0/24 md5
Решил, поменять метод авторизации с md5 на trust. Перезапускаю сервис и снова пробую подключится к БД. На этот раз получаю такое сообщение.  Действительно на сайте pgAdmin доступна уже более новая версия. После чего подключение к БД завершается успехом!!?!! Помнится, ранее md5 не вызывал подобных проблем, видимо данный глюк действительно связан со старой версией pgAdmin’a.
Действительно на сайте pgAdmin доступна уже более новая версия. После чего подключение к БД завершается успехом!!?!! Помнится, ранее md5 не вызывал подобных проблем, видимо данный глюк действительно связан со старой версией pgAdmin’a.  Теперь можем создать базу для нужд 1С, либо сделать это при помощи самой 1С:)
Теперь можем создать базу для нужд 1С, либо сделать это при помощи самой 1С:)
2. Установка 1C предприятие 8.2.
Для установки отметим, следующие компоненты: 1С:Предприятие, Сервер 1С:Предприятия, Модули расширения веб-сервера, Администрирование сервера 1С:Предприятия.
 На этапе, установки «Установить 1С Предприятие как сервис», задаем пароль пользователю USR1C82.
На этапе, установки «Установить 1С Предприятие как сервис», задаем пароль пользователю USR1C82.  Нажимаем далее, следим за ходом установки:) Пользователю USR1CV82
при установке должны быть назначены следующие права:
Нажимаем далее, следим за ходом установки:) Пользователю USR1CV82
при установке должны быть назначены следующие права:
Вход в систему как сервис (Log on as a service), Вход в систему как пакетное задание (Log on as a batch job). Посмотреть можно в Local Computer Policy\Computer Configuration\Windows Setings\Security Setings\Local Policies\User Right Assigments.
Переходим в оснастку Администрирование серверов 1С Предприятие,
смотрим что кластер поднялся, и висит на 1541 порту. На вкладке «Рабочие серверы» так же присутствует наш сервер. Теперь, можно добавить базу на сервер 1С. Для этого переходим на вкладку «Информационные базы
» щелкаемся правой кнопкой и выбираем New — Информационная база
. Задаем необходимые параметры для подключения к серверу PostgreSQL. Нажимаем ОК.
Теперь, можно добавить базу на сервер 1С. Для этого переходим на вкладку «Информационные базы
» щелкаемся правой кнопкой и выбираем New — Информационная база
. Задаем необходимые параметры для подключения к серверу PostgreSQL. Нажимаем ОК. Запускаем 1С: Предприятие. Выбираем, добавить существующую информационную базу на сервере.
Запускаем 1С: Предприятие. Выбираем, добавить существующую информационную базу на сервере.  Далее, задаем параметры для подключения. Нажимаем «Далее» и наконец «Готово».
Далее, задаем параметры для подключения. Нажимаем «Далее» и наконец «Готово». Операцию по созданию базы, можно проделать напрямую из 1С: Предприятия. Для этого при запуске, выбираем пункт «Создание новой информационной базы».
Операцию по созданию базы, можно проделать напрямую из 1С: Предприятия. Для этого при запуске, выбираем пункт «Создание новой информационной базы».
 Для подключения клиентов 1С к серверу извне и работы сервера баз данных, на файрволе, должны быть открыты следующие порты:
Для подключения клиентов 1С к серверу извне и работы сервера баз данных, на файрволе, должны быть открыты следующие порты:
Агент сервера (ragent ) — tcp:1540 Главный менеджер кластера (rmngr ) — tcp:1541 Диапазон сетевых портов, для динамического распределения рабочих процессов — tcp:1560-1591, tcp:5432 — Postgresql. Создадим правило через стандартный интерфейс, либо с помощью команды:
netsh advfirewall firewall add rule name=»1Cv8-Server» dir=in action=allow protocol=TCP localport=1540,1541,5432,1560-1590 enable=yes profile=ANY remoteip=ANY interfacetype=LAN
Теперь с другого компьютера мы спокойно запускаем клиент 1С:Предприятия, добавляем существующую информационную базу newdb . Не забываем про лицензии, программной / аппаратной защиты. Теперь, можем загрузить тест Гилева и померить производительность нашей системы.
На VirtualBox с 1Гб памяти, Dual-Core 2.6 GHz, 319-релиз 1с, тест Гилева выдает — 11.42 баллов, примерно так же как на CentOS. На 16.362 чуть больше 11.60 баллов. Оптимизация настроек при помощи EnterpriseDB Tuning Wizard ощутимого прироста (11.66 и 11.62) не дала, хотя возможно в целом польза от него имеется. :)
3. Регламентные работы на сервере PostgreSQL.
Резервное копирование.
Запускаем утилиту администрирования pgAdmin III, щелкаемся правой кнопкой по нужной базе данных. Выбираем »Резервное копирование». 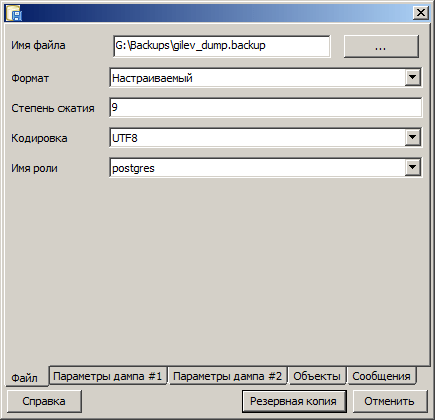 Выбираем формат (Настраиваемый (степень сжатия от 0 до 9), Tar, Простой, Каталог). По степени сжатия, лучше всего сжимает «настраиваемый формат» любой степени сжатия, затем «каталог», потом «простой» и наконец «tar». Кодировку указываем UTF8, имя роли postgresql. Все дополнительные опции оставляем по умолчанию. Нажимаем кнопку «Резервная копия». В поле «Сообщения» отображается список всех произведенных операций с кодом завершения. Если 0, то успех. Здесь же можно подсмотреть, как запустить подобную операцию из командной строки.
Выбираем формат (Настраиваемый (степень сжатия от 0 до 9), Tar, Простой, Каталог). По степени сжатия, лучше всего сжимает «настраиваемый формат» любой степени сжатия, затем «каталог», потом «простой» и наконец «tar». Кодировку указываем UTF8, имя роли postgresql. Все дополнительные опции оставляем по умолчанию. Нажимаем кнопку «Резервная копия». В поле «Сообщения» отображается список всех произведенных операций с кодом завершения. Если 0, то успех. Здесь же можно подсмотреть, как запустить подобную операцию из командной строки.
F)\pgAdmin III\1.16\pg_dump.exe" --host 192.168.1.200 --port 5432 --username "postgres" --role "postgres" --no-password --format custom --blobs --compress 9 --encoding UTF8 --verbose --file "G:\Backups\gilev_dump.backup" "newdb"
Соответственно, скрипт автоматического резервного копирования, который мы добавим в планировщик может выглядеть примерно следующим образом:
"C:\Program Files (x86)\pgAdmin III\1.16\pg_dump.exe" --host 192.168.1.200 --port 5432 --username "postgres" --role "postgres" --no-password --format custom --blobs --compress 9 --encoding UTF8 --verbose --file "G:\Backups\gilev_dump_%date:~0,2%_%date:~3,2%_%date:~6,4%.backup" "newdb"
Восстановление.
Для восстановления, выбираем базу, в которую хотим восстановить данные из резервной копии, желательно в пустую. Щелкаемся правой кнопкой и выбираем «Восстановление». Задаем файл бэкапа, имя роли: postgres, нажимаем «Восстановить»  С помощью командной строки:
С помощью командной строки:
"C:\Program Files (x86)\pgAdmin III\1.16\pg_restore.exe" --host 192.168.1.200 --port 5432 --username "postgres" --dbname "testdb" --role "postgres" --no-password --verbose "G:\Backups\gilev_dump_26_09_2012.backup"
где, testdb — пустая база, в которую восстанавливается архив резервной копии.
Операции по обслуживанию:
Команда VACUUM (Сжатие):
Последовательно чистит все таблицы базы данных, подключенной в настоящий момент, удаляет временные данные и освобождает место на диске. Чаще всего команда VACUUM выполняется именно для получения максимального объема свободного дискового пространства на диске и увеличения скорости доступа к данным.
 VACUUM
— помечает место, занимаемое старыми версиями записей, как свободное. Использование этого варианта команды, как правило, не уменьшает размер файла, содержащего таблицу, но позволяет не дать ему бесконтрольно расти, зафиксировав на некотором приемлемом уровне. При работе VACUUM возможен параллельный доступ к обрабатываемой таблице. Существует несколько дополнительных опций использования VACUUM: VACUUM FULL, VACUUM FREEZE, VACUUM ANALYZE.
VACUUM
— помечает место, занимаемое старыми версиями записей, как свободное. Использование этого варианта команды, как правило, не уменьшает размер файла, содержащего таблицу, но позволяет не дать ему бесконтрольно расти, зафиксировав на некотором приемлемом уровне. При работе VACUUM возможен параллельный доступ к обрабатываемой таблице. Существует несколько дополнительных опций использования VACUUM: VACUUM FULL, VACUUM FREEZE, VACUUM ANALYZE.
VACUUM FULL — пытается удалить все старые версии записей и, соответственно, уменьшить размер файла, содержащего таблицу. Этот вариант команды полностью блокирует обрабатываемую таблицу.
VACUUM FREEZE — Если VACUUM FULL удаляет «мусор» из таблиц и перемещает записи так, чтобы таблицы располагались на диске компактно и состояли из наименьшего числа фрагментов, при этом сжатие выполняется долго и блокирует записи, то VACUUM FREEZE просто удаляет «мусор» из таблиц, но сами записи не перемещает, поэтому выполняется быстрее и не блокирует записи. В настоящий момент эту опцию заменяет autovacuum — автоматическая сборка мусора в postgresql.conf плюс несколько дополнительных опций расширяющих функциональность:
autovacuum = on
# Включает автоматическую сборку мусора.
log_autovacuum_min_duration = -1
# Установка равная нулю регистрирует все действия autovacuum. Минус один (по умолчанию) запрещает вывод в лог. Например, если вы установите значение
равное 250 мс, то все действия autovacuum и analyzes, которые работают 250 мс и более, будут заноситься в журнал. Включение этого параметра может быть полезно для отслеживания autovacuum.
Этот параметр может быть установлен только в файле postgresql.conf или в командной строке сервера.
autovacuum_naptime = 10min
# Время в секундах через которое база данных проверяется на необходимость в сборке мусора. По умолчанию это происходит раз в минуту.
autovacuum_vacuum_threshold
= 1800 # Порог на число удалённых и изменённых записей в любой таблице по превышению которого происходит сборка мусора (VACUUM).
autovacuum_analyze_threshold
= 900 # Порог на число вставленных, удалённых и изменённых записей в любой таблице по превышению которого запускается процесс анализа (ANALYZE).
autovacuum_vacuum_scale_factor
= 0.2 # Процент изменённых и удалённых записей по отношению к таблице по превышению которого запускается сборка мусора.
autovacuum_analyze_scale_factor
= 0.1 # То же, что и предыдущая переменная, но по отношению к анализу.
VACUUM ANALYZE
— Если в базе есть таблицы, данные в которых не изменяются и не удаляются, а лишь добавляются, то для таких таблиц можно использовать отдельную команду ANALYZE. Также стоит использовать эту команду для отдельной таблицы после добавления в неё большого количества записей.
Команда ANALYZE (Анализ):
Служит для обновления информации о распределении данных в таблице. Эта информация используется оптимизатором для выбора наиболее быстрого плана выполнения запроса. Обычно команда используется в связке с VACUUM ANALYZE .
Команда REINDEX (переиндексация):
Используется для перестройки существующих индексов. Использовать её имеет смысл в случае
— порчи индекса;
— постоянного увеличения его размера.
Второй случай требует пояснений. Индекс, как и таблица, содержит блоки со старыми версиями записей. PostgreSQL не всегда может заново использовать эти блоки, и поэтому файл с индексом постепенно увеличивается в размерах. Если данные в таблице часто меняются, то расти он может весьма быстро. Если вы заметили подобное поведение какого-то индекса, то стоит настроить для него периодическое выполнение команды REINDEX. Учтите: команда REINDEX, как и VACUUM FULL, полностью блокирует таблицу, поэтому выполнять её надо тогда, когда загрузка сервера минимальна.
Bluetooth

